Gautham Vasan
 Privat
Privat
Gautham Vasan vor dem Karlsruher Schloss
"Ich freue mich, eine Momentaufnahme meiner Forschung an der Universität Freiburg teilen zu können, wo ich mit Prof. Joschka Boedecker an der Implementierung von Reinforcement Learning bei Medizinrobotern arbeitete. Während dieses Forschungsaufenthalts hatte ich das Vergnügen, mit anderen Forschenden zusammenzuarbeiten und von ihnen zu lernen, was sowohl meine wissenschaftlichen Bestrebungen als auch mein persönliches Wachstum gefördert hat."
Gautham Vasan befasst sich mit der Steuerung von Assistenzrobotern durch neuronale Schnittstellen. Durch das UNICORE-Stipendium kam er nach Freiburg an die Universität.
Er teilt etwas von seiner akademischen und persönlichen Reise:
Das Hauptergebnis meines Forschungsaufenthalts war die Entwicklung eines neuen Lernverfahrens namens Composite Soft Actor-Critic, das besonders effektiv bei Aufgaben sein kann, bei denen ein Akteur mittels Versuch-und-Irrtum-Interaktionen mit seiner Umwelt eine Steuerungsstrategie erlernen soll.
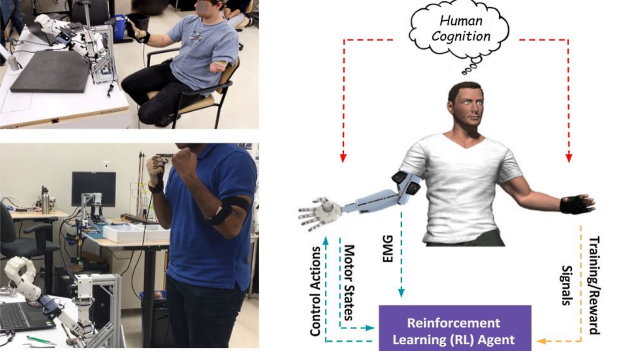
Das Hauptziel unseres Projekts ist die Integration sehr verrauschter Signale, die aus dem Gehirn eines Patienten dekodiert wurden, darunter auch Informationen zu Präferenz und Misserfolg, in ein Reinforcement Learning (RL)-Gerüst [1] einschließlich der Auswertung dieses Aufbaus für Fertigkeitserwerb und Anpassung von Assistenzrobotern.
Langfristig hoffen wir, daraus ein probeneffizientes und intuitives Verfahren zur Steuerung verschiedener technischer Systeme mithilfe von Gehirnsignalen und zur Anpassung an die Präferenzen und Bedürfnisse des Nutzers entwickeln zu können. Als ersten Schritt zu diesem ehrgeizigen Ziel arbeiteten wir an der Entwicklung eines robusten, probeneffizienten Lernalgorithmus, der mit verrauschten Belohnungssignalen (Präferenzinformationen eines Nutzers) zurechtkommt.

Github Gautham Vasan
Gespiegeltes bilaterales Prothesentraining mittels Actor-Critic Reinforcement Learning
Soft Actor-Critic ist ein Algorithmus auf dem neuesten Stand der Technik auf dem Gebiet RL, der speziell auf kontinuierliche Aktionsräume ausgelegt ist. Dieses Verfahren ist zwar bei den meisten klassischen Aufgaben in der Robotik das leistungsfähigste, doch es ist nicht gut auf verrauschte Belohnungssignale und langfristig ausgerichtete Aufgaben ausgelegt. Das Composite Q-Learning ist ein Off-Policy Reinforcement Learning-Verfahren, bei dem der langfristige Wert in kleinere Zeiträume geteilt wird. Dieser Algorithmus hat sich als robust gegen verrauschte Belohnungssignale erwiesen und eignet sich gut für langfristig ausgerichtete Aufgaben. Allerdings ist er empfindlich bei der Wahl der Hyperparameter und nicht so robust wie Soft Actor-Critic.
Wir kombinieren die Konzepte zweier bereits existierender RL-Algorithmen, nämlich Composite Q-Learning [2] und Soft Actor-Critic [3], und entwickeln so ein neues Lernverfahren namens "Composite Soft Actor-Critic". Diese Forschungslinie beinhaltet Experimente mit fortgeschrittenen Optimierungsverfahren, Belohnungsmodellierung und mathematischen Ableitungen, um die Konzepte des Composite Q-Learning auf Soft Actor-Critic auszuweiten. Mit unserem Ansatz können die Probleme möglicherweise umgangen werden, die die ursprünglichen Verfahren plagen.
Dank der Anleitung durch meine Mentoren und des Antriebs durch die Diskussionen mit meinen Kolleginnen und Kollegen entwickelt sich mein Projekt zu einer potenziellen Veröffentlichung bei IEEE Robotics and Automation Letters. Nun, da mir diese Ergebnisse vorliegen, freue ich mich darauf, sie in reale Anwendungen zu integrieren, vor allem anhand von Studien über EEG-Signalfeedback von menschlichen Nutzern.
Github Gautham Vasan
Lernen durch Demonstration: Lernen einer myoelektrischen Prothese mit einer intakten Gliedmaße durch Verstärkungslernen
Die wissenschaftliche Atmosphäre an der Universität Freiburg war belebend. Die KI-Labore, der interdisziplinäre Dialog und der kollaborative Ethos der Universität boten fruchtbaren Boden für die Forschung. Die Teilnahme an Workshops und Seminaren öffnete mir Türen zu neuen Blickwinkeln, was Innovation förderte und meine Horizonte erweiterte. Ich bedanke mich besonders bei Joschka Boedecker, Erfan Azad, Jan Ole von Hartz, Jasper Hoffmann, Lisa Graf und Gabriel Kalweit für diverse aufschlussreiche Diskussionen und Feedback zu meiner Arbeit.
Die Erfahrungen, die ich als Inder in Deutschland gemacht habe, waren wundervoll. Alltägliche Erlebnisse wie die Erkundung des Schwarzwaldes und das Genießen örtlicher Feierlichkeiten machten meine Reise noch einprägsamer. Kleine kulturelle Unterschiede wie die Gepflogenheit, dass Universitätsstudierende nach jeder Vorlesung mit den Knöcheln auf den Tisch klopfen, sind wirklich faszinierend, um es gelinde auszudrücken. Meine Deutschkompetenzen sind zwar nicht gut, aber die Einheimischen waren immer freundlich und hilfsbereit, wenn ich nach dem Weg und nach Empfehlungen für den Raum in und um Freiburg fragte.
Meine Zeit an der Universität Freiburg hat mich tief geprägt. Durch den Zugang zu erstklassiger Forschung, den Dialog mit Experten und die Anpassung an ein neues akademisches Umfeld wurden meine Kompetenzen geschärft, wodurch der Grundstein für meine zukünftige Forschung und Karriereentwicklung gelegt wurde. Außerhalb des akademischen Bereichs knüpfte ich Kontakte, die Grenzen überwinden. Die Vermischung von Kulturen und der intellektuelle Austausch nährte Freundschaften, die mit Sicherheit noch lange währen werden. Unter all den kostbaren Erinnerungen stechen besonders das Wandern in der Schwarzwaldregion und das Bier am Kastaniengarten als einzigartige Erlebnisse kulturellen Eintauchens hervor.
Im Großen und Ganzen lässt sich sagen, dass mein Forschungsaufenthalt an der Universität Freiburg eine Reise voller Innovation, Zusammenarbeit und persönlicher Entwicklung war. Das Zusammenspiel fokussierter Forschung, kulturellen Eintauchens und wissenschaftlicher Kameradschaft hat mich auf einen aufregenden Pfad auf dem Gebiet des Reinforcement Learning katapultiert.
Stand: August 2023. Die englische Version ist das Original.



